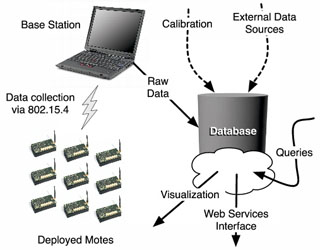
System ArchitectureData Collection SubsystemThe data collection subsystem includes the motes and the base station illustrated in Figure 1. We use MicaZ motes from Crossbow Inc. Each mote is connected to an MTS101 data acquisition board providing ambient light and temperature sensors in addition to ports for up to five external sensors. We attach two sensors to these ports: a Watermark soil moisture sensor and a soil thermistor, both available from
Motes sample data every minute and store them on a circular buffer in their local flash. We use the on-board flash memory so that we can retrieve all observed data even over lossy wireless links -- in contrast to sample-and-collect schemes such as TinyDB which can lose up to 50% of the collected measurements [TPS+05]. Since the mote collects 23KB per day, the MicaZ 512KB flash measurements will be overwritten if not collected within 22 days. In practice, the sensor measurements we downloaded from the motes weekly or at least once every two weeks. To ensure reliable delivery, the base station requests the mote's stored data using a simple sliding window ARQ protocol, and stores the retrieved measurements in the database.
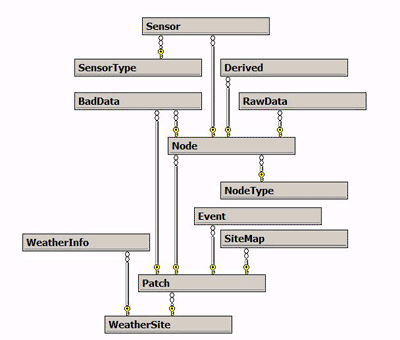
DatabaseThe database design follows naturally from the experimental design and the WSN. The experimental layout is broken into Patches which contain Nodes (motes). There are types of Nodes and types of Sensors that are described in the type tables. Each Node has a descriptive record in the Nodes table. Each Node has one or more Sensors. Each sensor has a table entry describing the details of that object. The Event table records state changes of the experiment such as battery changes, maintenance, site visits, replacement of a sensor, etc. Global events are represented by pointing to a NULL patch or a NULL node. Measurements are recorded in the Raw and Derived (calibrated) tables. External weather data is recorded in the WeatherInfo table. Various support tables contain lookup values for the sensor calibrations. Figure 2. shows the database schema.
The database, implemented in Microsoft SQL Server 2005, benefits from the skyserver.sdss.org database we built for Astronomy applications. It inherited a self-documenting framework that uses embedded markup tags in the comments of the DDL scripts to characterize the metadata (units, descriptions, enumerations, etc.) for the database objects, tables, views, stored procedures, and columns. The DDL is parsed a second time, and the metadata information is extracted and inserted into the database itself. A set of stored procedures generate an HTML rendering of the hyperlinked documentation (see Schema Browser on our website. Data LoadingThe hardware configuration (Patch, Node, Sensor) and sensor calibrations are preloaded before data collection begins. When new motes or sensors are added, new records are added to those tables. When new types of motes or sensors are added, those types are added to the database type tables.To date we have loaded 1.6M readings of 3-5 sensors per node, for a total of 6M data points. Raw measurements arrive from the base station as ASCII files in comma-separated-list format. The data are first loaded into a temporary table, where duplicates are removed. The data is next copied into the RawData table, with the \textit{processed} flag set to 0. Converting the raw data to scientifically meaningful values requires a multi-step pipeline performed within the database as a stored procedure. The conversions apply to all $processed = 0$ RawData values. Each produces a Derived measurement and the \textit{RawData.processed} flag is set to 1. The interface boards on some sensors had a loose connection for a while. These RawData measurements are invalid. These intervals are represented in a BadData table, and the corresponding rows in the Derived table are marked with an \textit{isBad=1} flag. Background weather data from the BWI airport is harvested monthly in CSV format from \verb|wunderground.com| and loaded into the WeatherInfo table. This data includes temperature, precipitation, humidity, pressure and weather events (rain, snow, thunderstorm, etc).
CalibrationKnowing and decreasing the sensor uncertainty requires a thorough calibration process. To alleviate errors due to sensor variation we test them for both precision (how consistent individual sensors are) and accuracy (how close are they to the actual measurement). Moisture sensor precision is tested with eight sensors in buckets of wet sand measuring their resistance every ten minutes while varying the temperature from 0$^\circ$C to 35$^\circ$C over 24 hours. We found that six sensors gave similar readings, but two did not. These outliers need to be identified and replaced before deployment.We also performed a preliminary check with the soil thermistors and found they are ``relatively'' precise (±0.5°C), yet consistently returned values 1.5$^\circ$C below a NIST approved thermocouple. The 1.5°C bias does not present a large problem because we used the manufacturer's regression technique to convert resistance to temperature. Furthermore, there is 10 kΩ reference resistance connected in series with the moisture sensors on each mote. Since their value directly factors into the estimation of the sensor resistance, the bias is individually measured, recorded in the database, and used during the conversion from raw to derived temperature. Individual calibration clearly offers us a powerful tool to reduce the measurements' error bar, but how can it be accomplished? The temperature sensors can be calibrated relatively easily as their output (resistance) is only a function of temperature but the moisture sensors require a two-dimensional function that relates resistance to both soil moisture and temperature. The method we used to individually calibrate a Watermark is by taking resistance values at nine points (three moisture contents each at three temperatures), and use these values to calculate individual coefficients to an already published regression form.
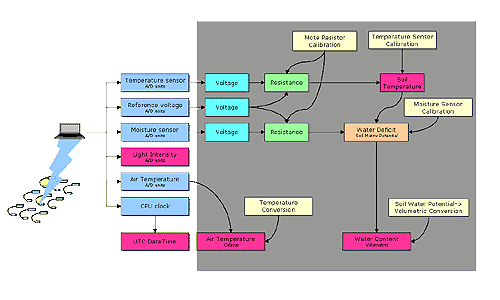
Figure 3 illustrates the data flow in the calibration pipeline. This pipeline, implemented within the database, gives the precision and accuracy necessary for sensor-based science. Data Access and AnalysisWe use several stored procedures and user defined functions to access the data in various aggregated forms. These functions are accessible through a few web-form interfaces that present tabulated values for all the sensors on a given node or for one sensor type across all nodes.The user can specify a window of interest (typically several days), and also a time-step over which the sensor reading are averaged over (a few hours). In another form the users can enter free form SQL for unlimited access to any data item in the database. Outputs can be formatted as HTML rendered tables, CSV files, or XML documents. We also provide a Web Services interface to display the node locations on a map, the values of a particular sensor displayed in color. The time series data can also be displayed in a graphical format, using a .NET web service, calling the same underlying functions or using the built-in SQL Server Reporting Services. This is an area that needs considerably more work -- soil scientists do not want to learn SQL and they often want to see graphical and spatial displays rather than tables of numbers. Beyond better reporting, we plan to use database OLAP and data mining tools. In addition to analyzing the low level readings looking for unusual cases, ecologists analyze aggregations and averages of the sensor data. We are implementing datacube of the measurements so that spatial and temporal averaging and correlation functions can be displayed more easily and quickly. These aggregates pivot on several dimensions: position on the hillside, depth in the soil, shade vs in the open, etc. This OLAP data cube, using SQL Server Analysis Services will be accessible via the web and web services interface. |